

What is NER Model and How It Works
A NER model (Named Entity Recognition model) is a cornerstone of NLP that identifies and classifies entities in text. In a world where unstructured data is growing exponentially, extracting meaningful information has become critical for businesses. This ability to analyze and organize textual data has made NER essential across various industries.
In today’s writing, we’ll explain to you what exactly named entity recognition is and its concept with a simple example. Moreover, you’ll discover various use cases of NER and gain a grasp of how it works.
What is Named Entity Recognition?

Named Entity Recognition is a Natural Language Processing technique that identifies and categorizes specific entities in text. These entities could include people, organizations, locations, dates, numerical values, and more.
Obviously, NER is at the heart of this technology, enabling systems to structure unstructured text data by extracting meaningful insights. The NER model forms the backbone of many applications, such as chatbots, sentiment analysis, and search engines. According to a recent report, the global NLP market is expected to reach $156.80 billion by 2030. With the adoption of tools like NER, we can expect a brighter future for AI and ML in various aspects.
The Purpose of the NER Model
The primary goal of a Named Entity Recognition model is to transform raw text into a structured format for analysis. By categorizing key information, it helps businesses extract actionable insights from massive datasets. As a desirable result, this enables efficient decision-making and supports applications in industries like healthcare, finance, and customer service.
The Key Concept of the NER Model

Behind the scenes, NER relies on several key concepts and techniques to understand and process language effectively. Let’s explore these components in detail.
POS Tagging
Parts of Speech tagging, or POS tagging, is one of the foundational steps in building a NER model. It involves labeling each word in a sentence with its grammatical role, such as noun, verb, adjective, or adverb. For instance, in the sentence “The doctor visited Paris,” the model would tag doctor as a noun and visited as a verb.
This tagging is crucial for NER because it helps the model understand the role each word plays in the sentence. Namely, proper nouns are often indicative of names, places, or organizations. In that light, POS tagging provides context, enabling the model to make more accurate predictions when categorizing entities.
In essence, this tagging process allows the model to narrow its focus on words likely to be entities, enhancing its precision.
Corpus
A corpus is essentially a large collection of text used to train the Named Entity Recognition model. This dataset is annotated with labeled examples, such as marking names, locations, and dates. In a training corpus for a NER model, the sentence “Apple Inc. is based in California” would highlight Apple Inc. as an organization and California as a location.
The quality and diversity of the corpus directly affect the model’s performance. A well-rounded corpus ensures that NER can handle different text types, from formal business documents to informal social media posts. By learning patterns from the corpus, the model can generalize its understanding to process unseen data effectively.
Chunking
Next, we have chunking, also known as shallow parsing, which involves breaking sentences into smaller, manageable phrases or chunks. For example, the sentence “The quick brown fox jumped over the lazy dog” might be chunked into phrases like “The quick brown fox” and “over the lazy dog.”
In the context of NER, chunking helps group words together to identify entities. This concept of the NER model is particularly important for multi-word entities. In such cases, understanding the relationship between words is crucial for accurate recognition.
Word Embeddings
Word embeddings are mathematical representations of words in a multi-dimensional space. They are advanced representations of words in a numerical format, capturing their semantic meaning and contextual relationships.
In NER, embeddings such as Word2Vec, GloVe, or those generated by transformer-based models like BERT play a critical role. Specifically, these embeddings allow the model to understand both the literal meaning of a word and its relationship with other words in a sentence. This capability becomes particularly important for distinguishing entities in ambiguous or complex contexts. Without such deep analysis, surface-level approaches may fail to deliver accurate results.
A NER Example
Consider the sentence for testing a NER model: “Tesla announced that Elon Musk plans to open a new factory in Austin, Texas, by the end of 2025.”

NER model applied to the sentence using the displaCy Named Entity Visualizer.
In this sentence:
- “Tesla” is tagged as ORG, representing an organization or company.
- “Elon Musk” is labeled as PERSON, indicating it is an entity referring to a person’s name.
- “Austin” and “Texas” are classified as GPE, which stands for Geopolitical Entity, identifying specific cities or regions.
- “2025” is recognized as DATE, representing a temporal entity.
Essentially, if you want to automatically extract and categorize such named entities from text, NER is the technique to employ. In essence, it helps computers understand the meaning of text by identifying key elements and their relationships.
Key Use Cases of the NER Model
The Named Entity Recognition model has been driving innovation across diverse industries. By identifying and categorizing entities in unstructured text, it empowers businesses to streamline processes, enhance insights, and make data-driven decisions. Let’s explore some of the key applications of the NER model in various domains:
Information Retrieval
One of the primary applications of NER stands for information retrieval. In an era where vast amounts of data are generated daily, retrieving relevant information from unstructured text is important. Specifically, Named Entity Recognition excels at extracting entities such as names, locations, dates, or specific terms from extensive datasets. As a result, it becomes easier to index and search for relevant content.

The NER model is particularly useful in retrieving information from a mass amount of data.
Let’s take the legal industry as an example. The Named Entity Recognition model can extract case numbers, names of litigants, or verdict details from legal documents. Consequently, the case research process is speeded up. Similarly, in academia, researchers use it to pull critical information from scientific papers or study datasets, saving time and effort.
Automated Data Entry
Manual data entry is not only time-consuming but also prone to errors. The technology automates this process by identifying key information in text and categorizing it into structured formats. Particularly, the NER model is useful in industries like healthcare, where accurate data recording is vital for patient care.
To illustrate, a healthcare provider can use NER to extract patient names, medical conditions, and prescribed treatments from clinical notes. This data is then frictionlessly entered into electronic health records (EHRs), reducing administrative burden and enhancing accuracy. Correspondingly, the Named Entity Recognition model serves as an application of AI in finance. Specifically, it can automate the extraction of transaction details, account numbers, and dates from invoices or bank statements.
Sentiment Analysis Enhancement
Gauging the emotions or opinions expressed in text is the purpose of sentiment analysis, an AI tool often used in marketing and customer service. While traditional sentiment analysis provides an overall sentiment score, integrating NER technology enhances its granularity. The NER model identifies specific entities in the text, such as product names, service mentions, or competitors. By doing so, it enables organizations to pinpoint what customers are talking about and understand how they feel about it.
Let’s see an example. If a customer review says, “I loved the camera on the new Phone X, but the battery life is disappointing,” the model can identify Phone X as the product. Additionally, it can segment the sentiment related to its camera and battery life separately. This level of detail is invaluable for companies aiming to improve their offerings or customer experience.
In industries like retail and hospitality, customer feedback is key. Therefore, the Named Entity Recognition model drives actionable insights that help improve strategies and enhance customer satisfaction.
How NER Model Works
At its core, NER involves two main steps:
- Detecting entities within the text.
- Classifying these entities into specific categories.
Let’s get into more details:
Entity Detection
The foundational step in the NER model process is entity detection, also known as mention detection or entity spotting. It involves identifying fragments of text that may represent entities of interest. This phase is critical because it narrows the scope for further analysis. As a result, it ensures that only relevant parts of the text proceed to the next stage.

Entity spotting, the first step of the NER model in work, will detect and indicate relevant entities.
Tokenization
At the heart of entity detection is tokenization, a process that breaks down a sentence or document into smaller components called tokens. Tokens are typically words but can also include punctuation or symbols. For instance, in the sentence “OpenAI created ChatGPT in 2023,” the tokens might be OpenAI, created, ChatGPT, and 2023.
By segmenting text into manageable units, tokenization lays the groundwork for further processing. Resultantly, it enables the Named Entity Recognition model to isolate specific entities from the surrounding text.
Feature Extraction
Once tokens are identified, the NER model extracts meaningful features from them to determine their potential as entities. This step examines:
- Morphological Features: These analyze word structures, such as roots, prefixes, or suffixes, helping identify variations like run and running.
- Syntactic Features: These focus on the relationships between words in a sentence. In particular, identifying a noun following a verb as a potential entity.
- Semantic Features: These capture the broader meaning of a word in its context. Namely, the word bank could refer to a financial institution or the side of a river, depending on the sentence.
With these features in place, NER ensures it doesn’t overlook meaningful entities while filtering out irrelevant ones.
Entity Classification
The next step is entity classification, where detected entities are assigned to predefined categories based on their context and significance. This phase is critical for transforming raw text into structured insights.
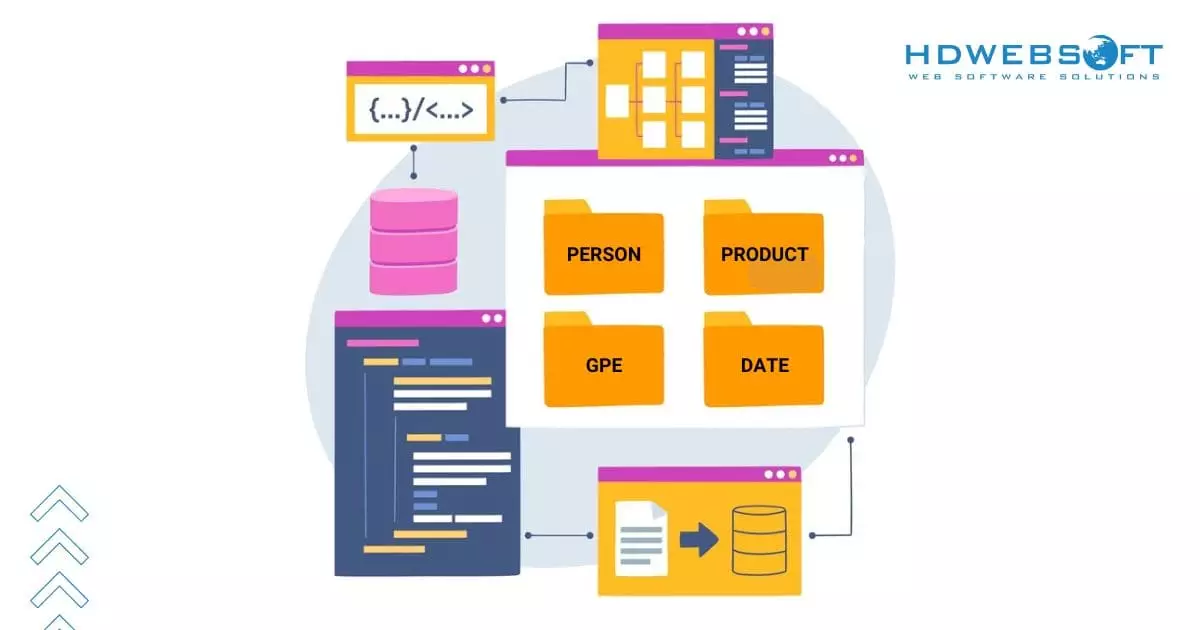
The next step is to classify the detected entities into prescribed categories.
Contextual Understanding
Effective entity classification in the NER model requires a nuanced understanding of the text’s context. For example, in the sentence “Amazon delivers goods worldwide,” Amazon would be classified as an organization. However, in “The Amazon rainforest is vast,” the same word represents a location.
To achieve this, the model relies on a combination of linguistic analysis and machine learning techniques, including:
- Rule-Based Approaches: Predefined rules and patterns, such as capitalization or specific word placements, help categorize entities.
- Statistical Models: Algorithms analyze patterns in annotated datasets to make predictions about an entity’s category.
- Deep Learning Models: Advanced architectures like BERT use word embeddings to capture the deeper contextual meaning, refining the classification process.
Managing Ambiguities
Natural language often contains ambiguities that challenge entity classification. For example, in “Spring arrives in March,” Spring refers to a season, but in “Spring Technologies launched a new app,” it’s an organization. Resolving such ambiguities demands sophisticated models trained on diverse and comprehensive datasets.
By effortlessly integrating entity detection and classification, the NER model transforms unstructured data into actionable insights. For this reason, it drives efficiencies across industries and applications.
Further reading: How is AI Text Analysis Used in Business?
The Challenges of the NER Model
The Named Entity Recognition technology has proven invaluable, yet it is not without its challenges. These obstacles often arise due to the complexities of human language and the inherent limitations of the technology. Let’s explore some of the most pressing challenges faced by the model.
Ambiguity
First and foremost, ambiguity is one of the most significant hurdles in NER. Words or phrases in natural language often carry multiple meanings, and determining which meaning applies in a context can be challenging.
Thus, this issue complicates identifying and categorizing entities, as the model must infer the correct meaning from limited information. Moreover, ambiguity increases the likelihood of errors, particularly in highly nuanced or domain-specific texts.
Context Dependency
Language is highly context-dependent, and this poses another layer of complexity for the NER model. The meaning and categorization of entities often rely on the surrounding words and phrases.
Think about it. A term that is an entity in one scenario might not hold the same significance in another. This dependency on contextual cues requires the model to possess a deep understanding of individual words. Additionally, it must comprehend how these words interact within the broader text.
Language Variations
In this world, language is diverse, with numerous dialects, idiomatic expressions, and unique grammatical structures. This diversity makes it challenging for NER to perform consistently across different languages or even variations within the same language. Furthermore, factors such as word order and syntactic differences can impact the model’s ability to identify and classify entities accurately.
The diversity of languages can be paramount for the NER model.
Data Sparsity
Another significant challenge is data sparsity. Many real-world applications require the model to handle specialized or less common data domains where annotated training datasets are scarce. Without sufficient training data, the NER model struggles to learn the patterns and relationships necessary for effective entity recognition.
Expectantly, this limitation can hinder its performance, especially when applied to niche fields or emerging topics.
Model Generalization
Last but not least, model generalization. It refers to the ability to perform well on new, unseen data that differs from its training dataset. Achieving this level of adaptability is particularly challenging because the language in real-world scenarios is diverse and unpredictable.
Hence, a model trained on specific datasets might fail to recognize or correctly classify entities in a completely different context. This, in turn, limits its scalability and usability across domains.
Conclusion
The NER model is revolutionizing how we process and analyze text, offering immense value across diverse industries. As the adoption of NLP grows, driven by advances in AI and increasing data volumes, the applications of NER are limitless. Whether in healthcare, finance, or customer service, NER stands out as a powerful tool in the AI toolbox. Organizations can expect to unlock the full potential of their unstructured data.
At HDWEBSOFT, we specialize in AI and ML development and can help businesses effortlessly integrate NER into their operations. Our expertise in artificial intelligence and natural language processing ensures that companies can efficiently harness the power of NER. Let us help you leverage this cutting-edge technology to stay ahead in today’s competitive landscape.






